人工知能(AI)がコンピューターゲーム“パックマン”のように学習データを食べ尽くす「学習データの枯渇問題」を一部識者が指摘している。学習に値するデータが底をついてAIの“成長モデル”が転換点を迎える、というのだ。“食べるもの”に事欠けば、AIは他の既存AIの生成データにも食指を伸ばすだろうが、そのデータは誤情報を含んだ“ジャンクフード”の可能性もある。データの枯渇問題は、AI にとっての学習データの量と質の重要性をあらためて認識させる。
「生成AIは、参照する情報の品質に回答の質が大きく左右される。どれほど高性能なAIモデルを使っても、参照元の情報が古く、不正確であったり、新版、旧版の複数の版の情報が混在している場合、誤った情報を提示してしまうリスクがある」
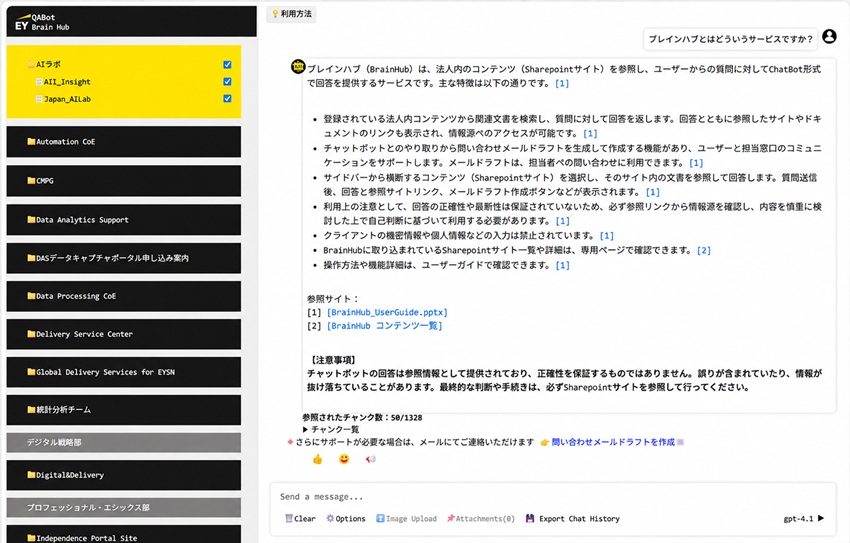
こう話すのは、EY新日本有限責任監査法人(東京都千代田区)のクライアントサービス本部イノベーション推進部 AIラボの岡田直樹さん。EY新日本で2025年4月に本格的に始まった企業向けAIアシスタントプラットフォーム「BrainHub(ブレインハブ)」の導入を担当した。岡田さんは「AIに何を答えさせるかを考える前に、AIが参照してよい情報は何か、を人間が整理する必要がある」とAIが参照するデータの“棚卸し”と整理が不可欠と強調する。

ブレインハブ導入前に徹底したのは「最新・正式情報の明確化」。社内関係12部署がSharePoint(シェアポイント)で管理、共有していた2202ページの情報を整理し、63%、1378ページを「公開済み」として認定。AIが参照すべき情報として絞り込んだ。草案や廃止予定の情報、更新が必要な情報は、AIの参照対象からすべて外した。この絞り込みは25年4月から約6カ月かかったという。
岡田さんは「これまで部署ごとに個別に整備されてきた情報を、AIが参照できる状態にするために複数の場所に分かれた同じテーマの情報を整理したり、管理ルールや更新責任を統一したりする必要があった。技術的な開発以上に、関係者の理解を得て、継続的に協力してもらうための合意形成が大きな課題だった」と振り返る。このため「ブレインハブのためだけではなく、今後Copilot(コパイロット)など生成AIの社内利用が広がる中で、コンテンツ整理は避けて通れない基盤づくりであることを各部署に説明した」という。
ブレインハブ導入に際しては「AIに判断を委ねすぎないこと」を設計の基本にしたという。具体的には、AIが回答時に参照できる情報の範囲を、人間があらかじめ区分し明確にする設計だ。すべての情報を一律にAIの検索対象にするのではなく、利用者が質問の対象となる情報コンテンツ領域を選べるようにした。こうすることで「AIが関係のない情報を参照して回答がぶれるリスクを抑え、利用者が、どの情報を前提にAIが回答しているかが分かる」からだ、という。
そのほか、社内で使用する情報と社外向けの情報は性質が異なるので、両者の情報区分を明示するようにした。また情報更新の責任体制を明確化し、AIに学習させる情報は週1回読み込み直す仕組みにした。その際、更新そのものを担うシステム側の責任者とは別に、更新情報“内容”の正確性を担保する各部署のコンテンツ責任者の責任を明確化した。
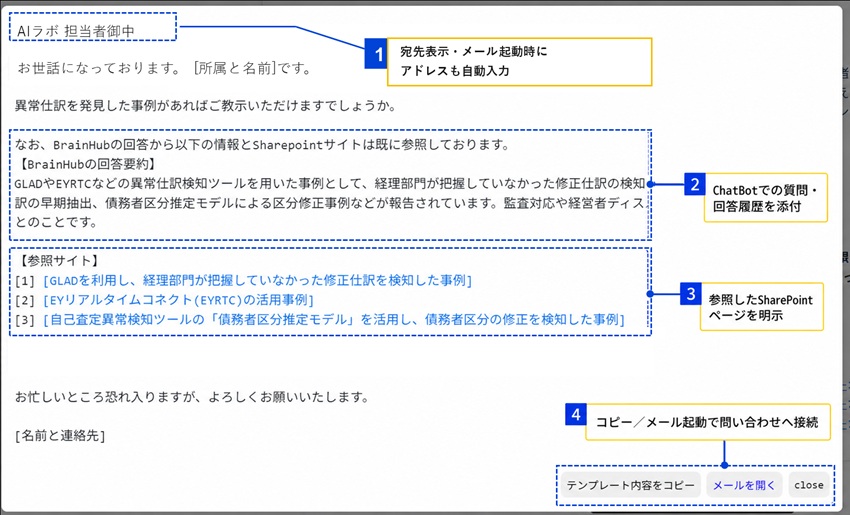
AIの回答が不十分な場合も想定し、利用者が担当部署へ問い合わせするボタンも組み込んだという。ボタンをクリックすると、問い合わせ先のメールアドレス、件名、チャットボット上での質問・回答の履歴、参照したシェアポイントページが入ったメール案が表示される。問い合わせを受けた側が、利用者がどの情報を見て、どこで分からなくなったのかを把握しやすくするための工夫だという。
これらのAI導入準備経験を踏まえ、岡田さんは、AIの有効活用が定着しない企業に対して「AI導入目的の明確化」を“助言”する。AI活用が定着しない企業の多くは「AI導入自体を目的としている」として、「社員が困っていることを分かりやすく、速く、確実に解決すること」がAI導入の目的であることをしっかり認識すべきと強調する。
その目的のもと、「AIが参照する情報を社内で使ってもよい最新・正式なデータに常に更新する仕組みを作りあげることが重要」と指摘する。